NOT IN vs NOT EXISTS, Who Would Win?
Based on a post from the prolific Pinal Dave:
In the fight between IN and EXISTS, who would win? In this case, specifically we look at the NOT variation of those.
Quick Setup
If you are familiar with my previous post about containerized SQL Server, you can very rapidly spin up a fresh SQL Server 2022 instance to take advantage of the handy new GENERATE_SERIES function for this demo.
USE testdb;
DROP TABLE IF EXISTS BigNumbers;
DROP TABLE IF EXISTS Numbers;
CREATE TABLE BigNumbers (
Id BIGINT );
CREATE TABLE Numbers (
Id INT );
GO
INSERT INTO BigNumbers
SELECT * FROM
GENERATE_SERIES ( 1, 2000000, 2)
INSERT INTO Numbers
SELECT * FROM
GENERATE_SERIES ( 1, 1000000, 4)
GO
Now we are going to step through this example.
Open a fresh query window or two in your testing database context.
You’ll want to turn on Actual Execution Plan, and run SET STATISTICS TIME,IO ON
The show
Note that our starting point is a NULLABLE column with no index. We are going to run both approaches between the two tables in both directions, to see if the row size difference has an impact in either direction.
SELECT ID FROM BigNumbers WHERE ID NOT IN ( SELECT ID FROM Numbers )
SELECT ID FROM BigNumbers WHERE NOT EXISTS ( SELECT * FROM Numbers WHERE Numbers.ID = BigNumbers.ID)
SELECT ID FROM Numbers WHERE ID NOT IN ( SELECT ID FROM BigNumbers )
SELECT ID FROM Numbers WHERE NOT EXISTS ( SELECT * FROM BigNumbers WHERE Numbers.ID = BigNumbers.ID)
GO
Look at everything the IN attempts to do…
(Images are clickable if they are too small to see)
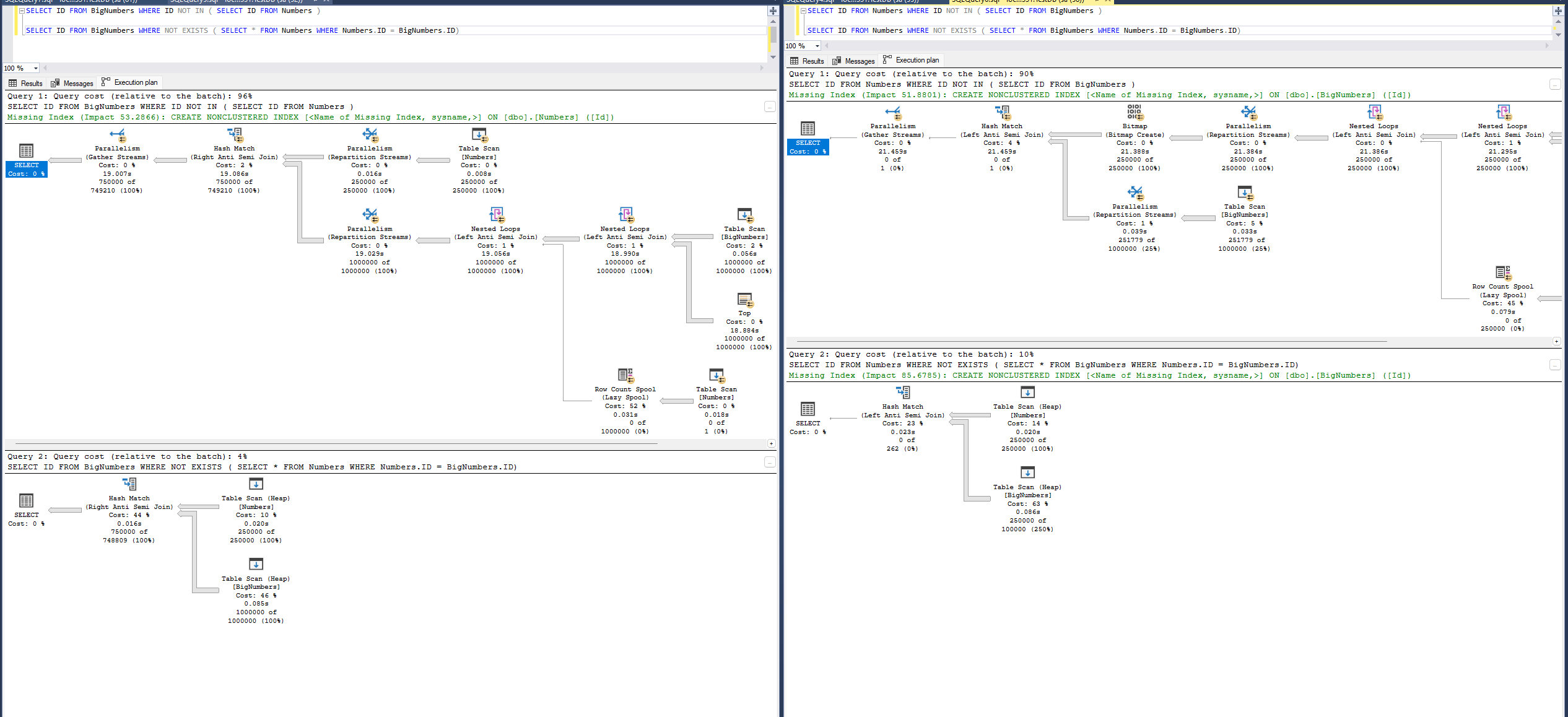
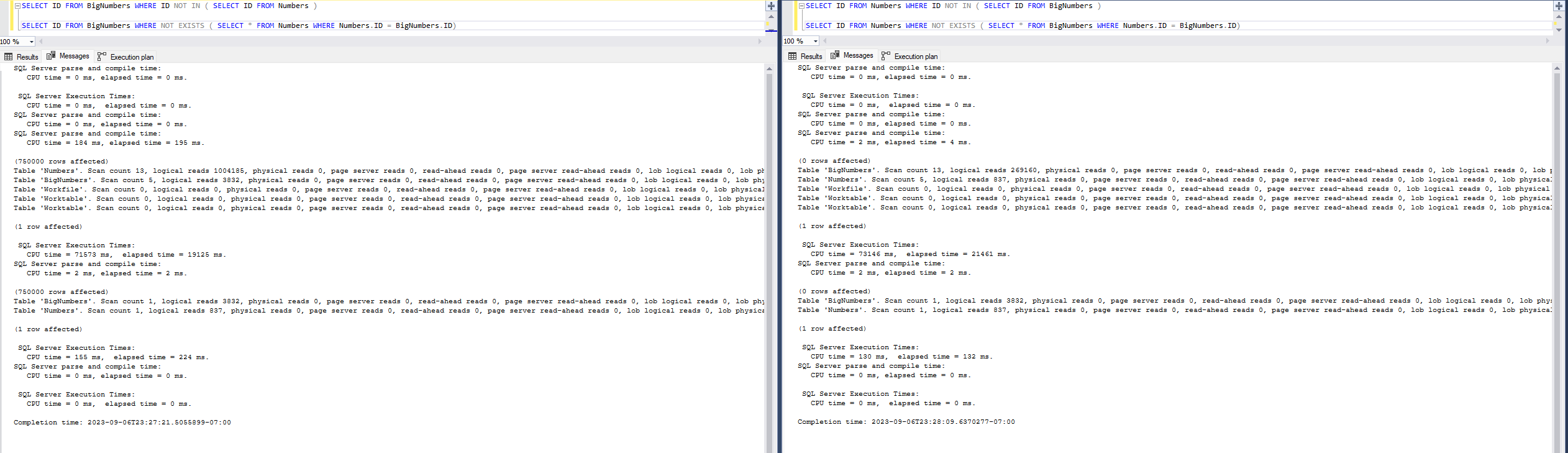
Keep in mind that the results of these two queries when a column actually has NULLs in it are different! In our case, we have a nullable column but no NULLs, so the engine must assume it’s POSSIBLE for one of the values to be NULL.
Now, let’s eliminate NULL handling from our concerns:
alter table BigNumbers alter column id bigint NOT NULL
alter table Numbers alter column id int NOT NULL
GO
And then we check our result from that change with the same 4 queries again:
SELECT ID FROM BigNumbers WHERE ID NOT IN ( SELECT ID FROM Numbers )
SELECT ID FROM BigNumbers WHERE NOT EXISTS ( SELECT * FROM Numbers WHERE Numbers.ID = BigNumbers.ID)
SELECT ID FROM Numbers WHERE ID NOT IN ( SELECT ID FROM BigNumbers )
SELECT ID FROM Numbers WHERE NOT EXISTS ( SELECT * FROM BigNumbers WHERE Numbers.ID = BigNumbers.ID)
GO
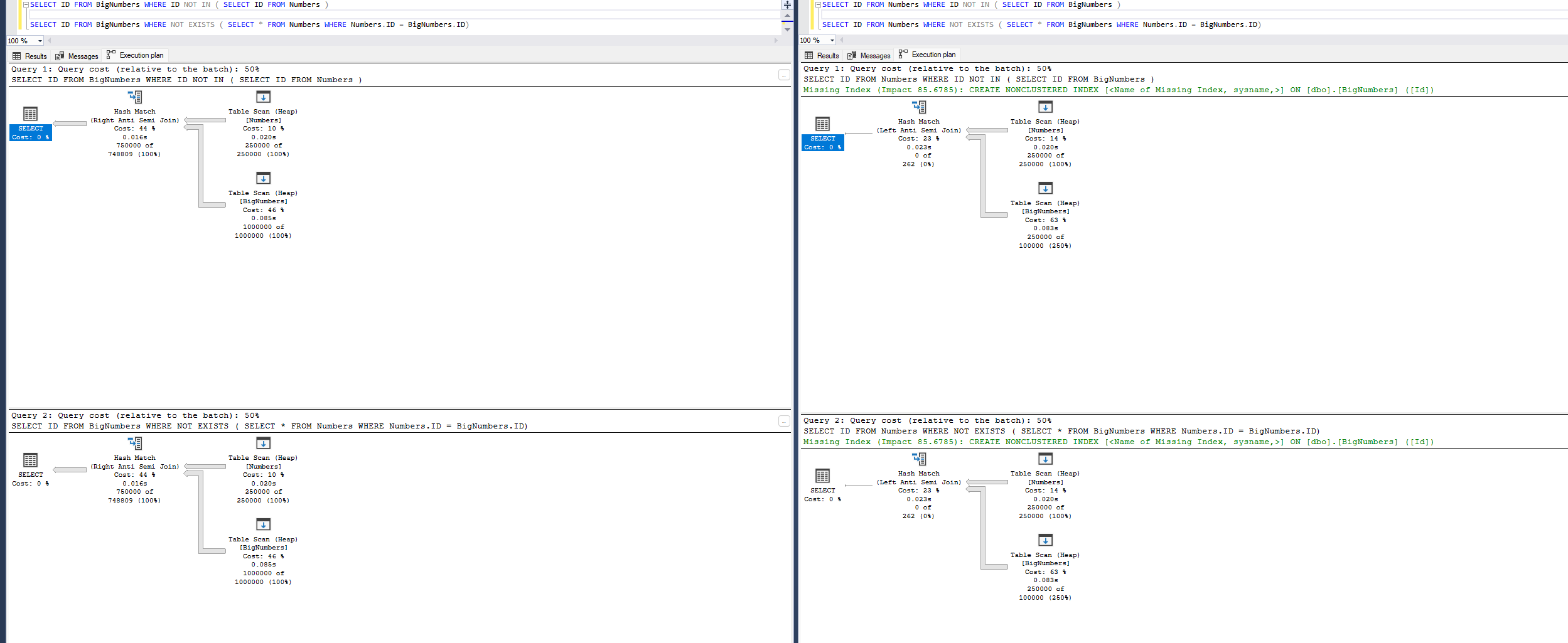
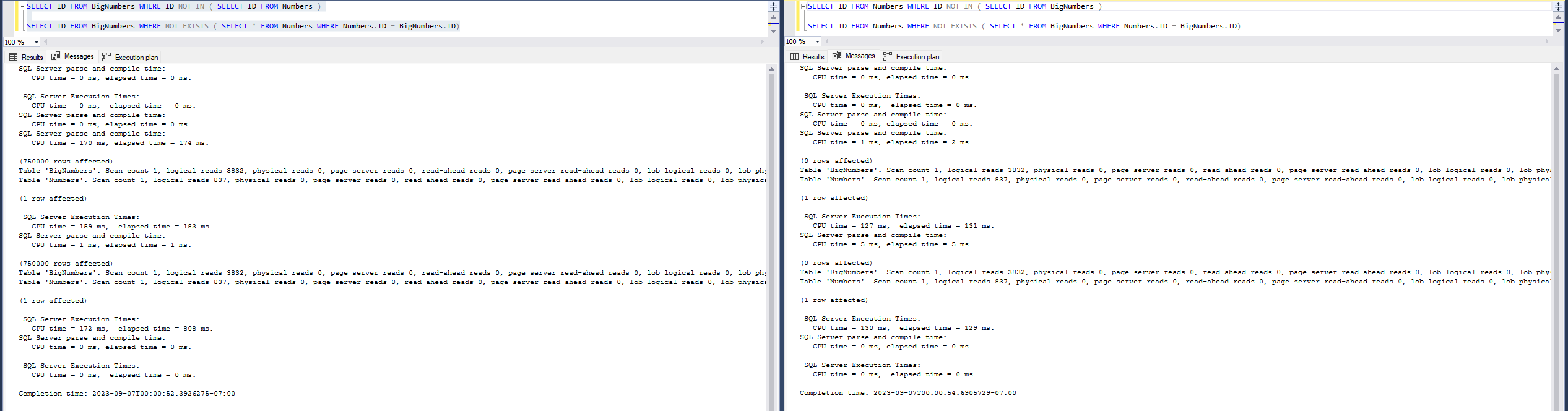
So as we can see clearly here, when null handling matters NOT EXISTS seems to take a major advantage in performance, but without the nullability concern it rapidly collapses down to the same query plan behind the scenes.
But! We can do better. Who wants a nasty old heap table lying around?
alter table BigNumbers add primary key (id )
alter table Numbers add primary key (id )
GO
Now with those columns identified as a Primary Key, they are enforced as both NOT NULL and UNIQUE, but also have a Clustered Index backing the column data.
What does that organization do for us?
SELECT ID FROM BigNumbers WHERE ID NOT IN ( SELECT ID FROM Numbers )
SELECT ID FROM BigNumbers WHERE NOT EXISTS ( SELECT * FROM Numbers WHERE Numbers.ID = BigNumbers.ID)
SELECT ID FROM Numbers WHERE ID NOT IN ( SELECT ID FROM BigNumbers )
SELECT ID FROM Numbers WHERE NOT EXISTS ( SELECT * FROM BigNumbers WHERE Numbers.ID = BigNumbers.ID)
GO
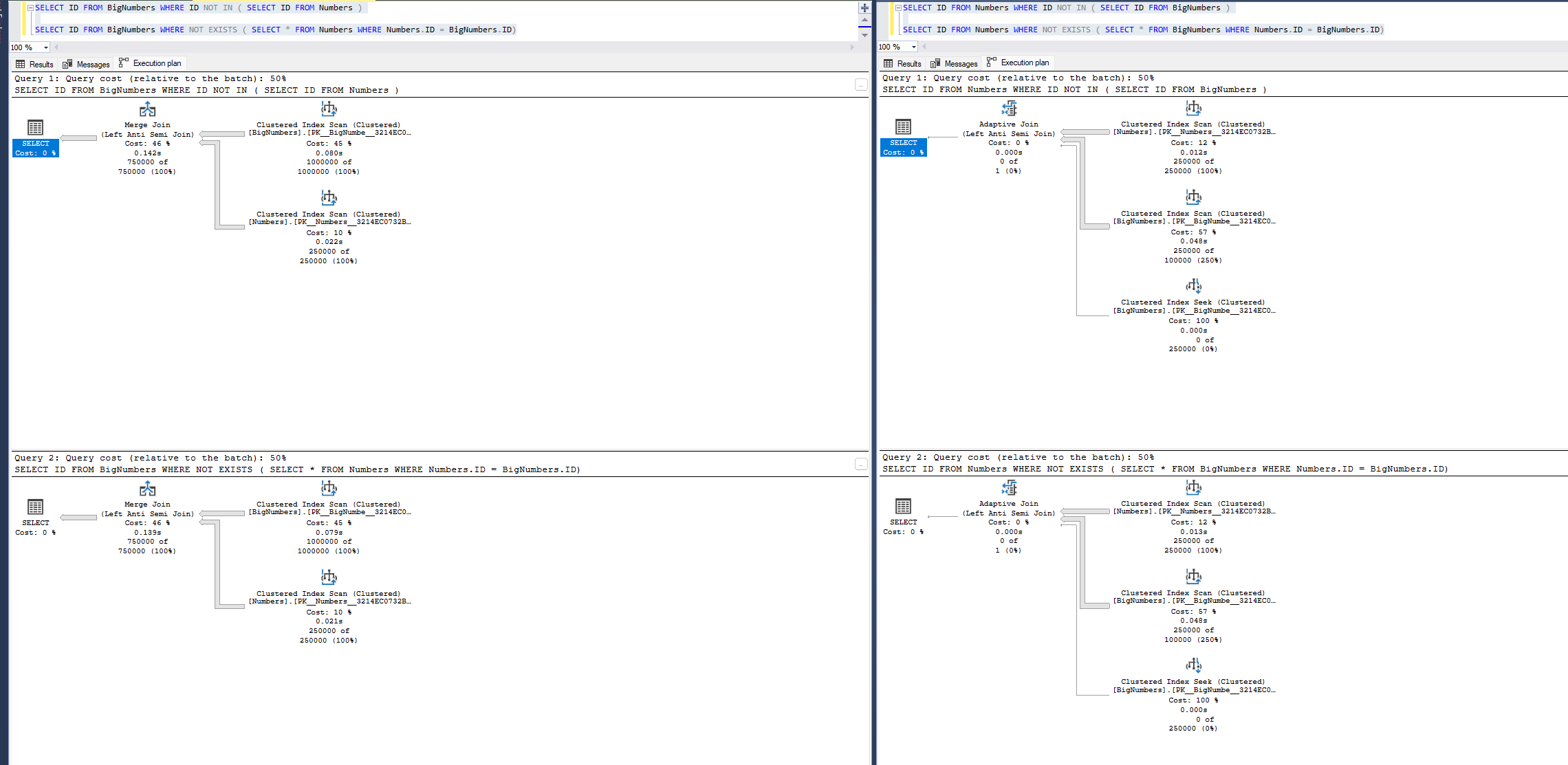
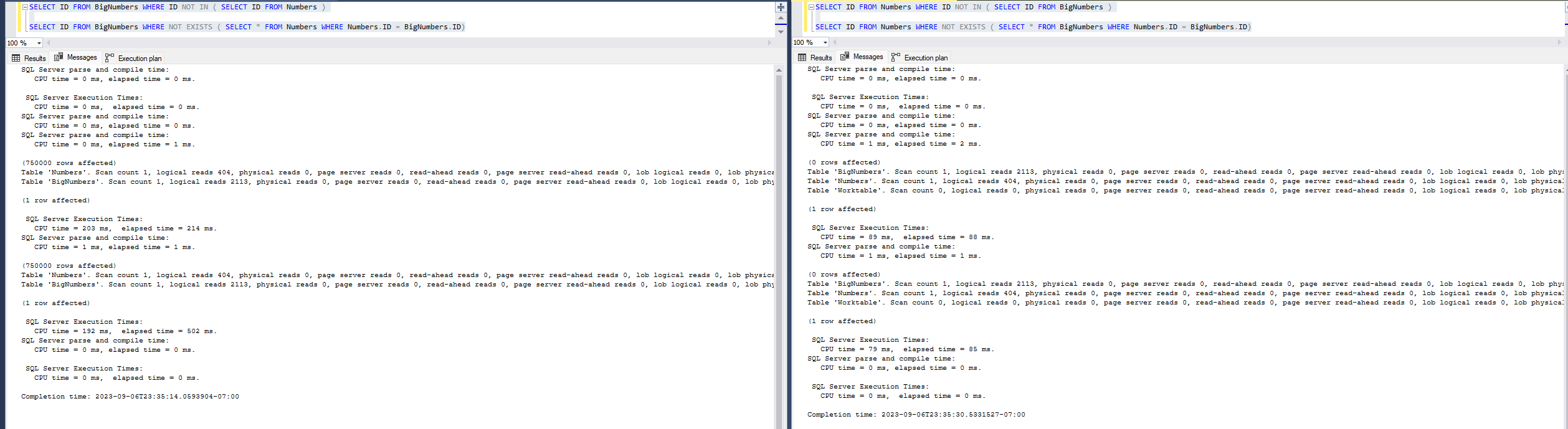
Our plans aren’t getting simpler, but our logical page reads dropped a nice chunk for such a simple example.
So we can see how in some cases, EXISTS and IN result in the exact behavior in the database engine, but depending on your circumstances you may find that EXISTS performs drastically better for you.
This is a call to remember a few things:
NULL handling can crop up in unexpected ways.
Proper constraints on your columns can really help!
INDEXING!
In Conclusion
